
1 Introduction
Cooperative multi‑agent reinforcement learning has enabled impressive coordination in tasks such as swarm robotics and autonomous navigation. However, the reliance on third‑party models or ability to swap model raises security concerns: an adversary could stealthily implant a backdoor into one agent’s policy that remains dormant until triggered, at which point it derails the entire team. To date, backdoor attacks in multi‑agent settings have assumed white‑box access—manipulating rewards or network parameters during training, which is unrealistic when policies are deployed as opaque services.
This project aims to develop a black-box approach for injecting a stealth backdoor into a single agent’s policy within cooperative multi-agent environments, such that triggering the backdoor can derail the entire team.
2 Related Work
Existing research on backdoor attacks in deep reinforcement learning (DRL) is limited. Furthermore, prior studies assume a white-box threat model in which the attacker has full access to the reward function during target-policy training. Although imitation learning is a well-established field, no previous work has explored implanting backdoors via imitation learning.
Current white-box techniques in multi-agent cooperative environments employ a range of triggers, including instantaneous observation-based triggers[1], external signal combine with a trigger policy[2], and spatiotemporal triggers[3][4].
During training, contemporary reward-hacking techniques include modifying the original reward function[1][3], distance between benign and abnormal observations[2], encouraging action discrepancies from other target agents when the backdoor is triggered[3][4], and, in more advanced schemes, learning fail observations to guide the policy[4].
3 Threat Model
3.1 Scenario and Attacker’s Objective
This project consider a possible attack scenario in which an attacker infiltrates a multi-agent distributed system by assuming the role of a user, either directly or via an outsourced model. Given a pre-trained clean cooperative policy (which could be rule-based rather than learned), the adversary can stealthily swap it for a malicious policy and deploy it in the team as a hidden “traitor” within the team.
The attacker’s objective is to compromise the entire team when the backdoor in a single agent is triggered. To achieve both effectiveness and stealth, the backdoored agent must (1) behave identically to clean agents in the absence of the trigger and (2) exhibit disruptive, malicious behavior upon trigger activation. Moreover, the trigger mechanism itself should be covert, rare, and require only a low poisoning rate.
3.2 Black-box Limitations
For this project, the black-box attack is subject to the following constraints:
- Policy Access The attacker may only query the target policy by providing an observation and receiving the corresponding action. No information about the policy’s logic, network architecture, or parameter values is available.
- Training ignorance The attacker has no prior knowledge of the policy’s training process, including the learning algorithm, reward function, or hyperparameters.
- Environment transparency The attacker has full access to the environment’s state-transition function, as the environment is assumed to be obtainable (e.g. publicly documented).
3.3 Problem Definition
In this section, the IMPOSTER agent in cooperative multi-agent environments is modeled as a decentralized partially observable Markov decision process (Dec-POMDP), defined by the tuple \((N, S, O, A, T, R, \gamma)\)
-
\(N = \{1, \dots, n\}\) denotes the set of team agents. Agent \(k\) is the backdoor-implanted IMPOSTER agent following policy \(\pi^I\); all other agents remain clean and follow the target policy \(\pi^T\).
-
\(S\) denotes the global environmental state space. Although \(S\) may be used to train the target policy, it remains unused for the IMPOSTER agent during both training and testing.
-
\(O = O_1 \times\dots\times O_n\) denotes the joint observations space of all agents. Each agent \(i\) receives a local observation \(o_{i,t} \in O_i\) at time step \(t\), which serves as an input to its policy network \(\pi^I\) for IMPOSTER agent or \(\pi^T\) for clean agents.
-
\(A = A_1 \times\dots\times A_n\) denotes the joint action space of all agents. IMPOSTER agent and each clean agent use \(\pi^I(a_{k, t} \mid o_{k, t}): O_k \rightarrow A_k\) and \(\pi^T(a_{i, t} \mid o_{i, t}): O_i \rightarrow A_i\) to select action, respectively, where \(a_{i, t} \in A_i\) denotes the selected action for agent \(i\) at time step \(t\).
-
\(T: S \times A \rightarrow S\) denotes the environment state transition function. Given state \(s_t \in S\) and joint action \(\mathbf{a}_t \in A\) at time step \(t\), \(T(s_{t + 1}\mid s_t, \mathbf{a}_t)\) denotes the probability of transitioning to state \(s_{t + 1} \in S\) at time step \(t + 1\). Similarly, \(F(o_{t + 1}\mid o_t, \mathbf{a}_t)\) is used to denote the observation transition of agent \(i\).
-
\(R: S \times A \rightarrow \mathbb{R}\) denotes the reward function for agent. After executing joint action \(\mathbf{a}_t \in A\) in state \(s_t \in S\) at time step \(t\), agent \(i\) will receive reward \(r_{i, t} = R(s_t, \mathbf{a}_t)\). Note, under the black-box constraint \(R\) is unknown to the attacker.
-
\(\gamma\) denotes the temporal discount factor where \(0 \leq \gamma \leq 1\).
In this project, only a single agent is implanted with the backdoor to preserve stealth and practicality. In the absence of the pre-defined trigger, the backdoored agent behaves identically to clean agents. Once the trigger occurs, however, it switches to disruptive behaviors that influence its teammates and ultimately cause the team to fail.
4 Methodology
4.1 R2D2
Recurrent Replay Distributed DQN (R2D2)[5], extends the Ape-X distributed architecture[6] by integrating an LSTM layer after the convolutional encoder, enabling agent to handle partial observation and long-horizon dependencies through sequence modeling. R2D2 combines n-step return targets, double Q-learning, dueling networks, and prioritized sampling. It also store the recurrent hidden states and employs burn-in portion to mitigate the issue caused by zero start states and replaying whole episode trajectories. R2D2 was the first agent to exceed human-level performance in 52 of the 57 Atari games.
4.2 SQIL
Soft Q Imitation Learning (SQIL)[7] is a straightforward imitation learning algorithm that can be integrated into any standard Q-learning or off-policy actor-critic algorithm with only minor modifications:
- Seed the experience replay buffer with expert demonstrations, assigning each transition a constant reward \(r = +1\).
- Collect oline experiences by interacting with the environment, add the new experiences to the replay buffer with reward \(r = 0\).
- Ensure balanced sampling by drawing equally from expert and online experiences (i.e. 50% each) when updating the agent.
4.3 Proposed Method
4.3.1 Spatiotemporal Backdoor Trigger
This project adopts a pre-defined spatiotemporal trigger which will be implanted into the IMPOSTER policy during training. The observation of each agent typically include four types of information: its own state, teammates’ state, internal environmental information, and external inputs. The backdoor attack can be triggered when a particular environmental state aries or when an attacker-controlled external input is detected.
A trigger is denoted as \(\Psi = \psi_T \land \dots \land \psi_{T + L - 1}\), where \(T\) is the starting time step of the trigger, \(L\) is the length of the trigger, and for each \(t \in \{T, \dots, T + L - 1\}\), \(\psi_t = C(o_{k, t})\). \(C\) and be any compare operation, for instance, the observation is zero (\(o_{k, t} = \mathbf{0}\)), or the \(i\)-th feature is between 0 and 1 (\(0 \leq o_{k, t, i} \leq 1\)).
4.3.2 Attack Framework
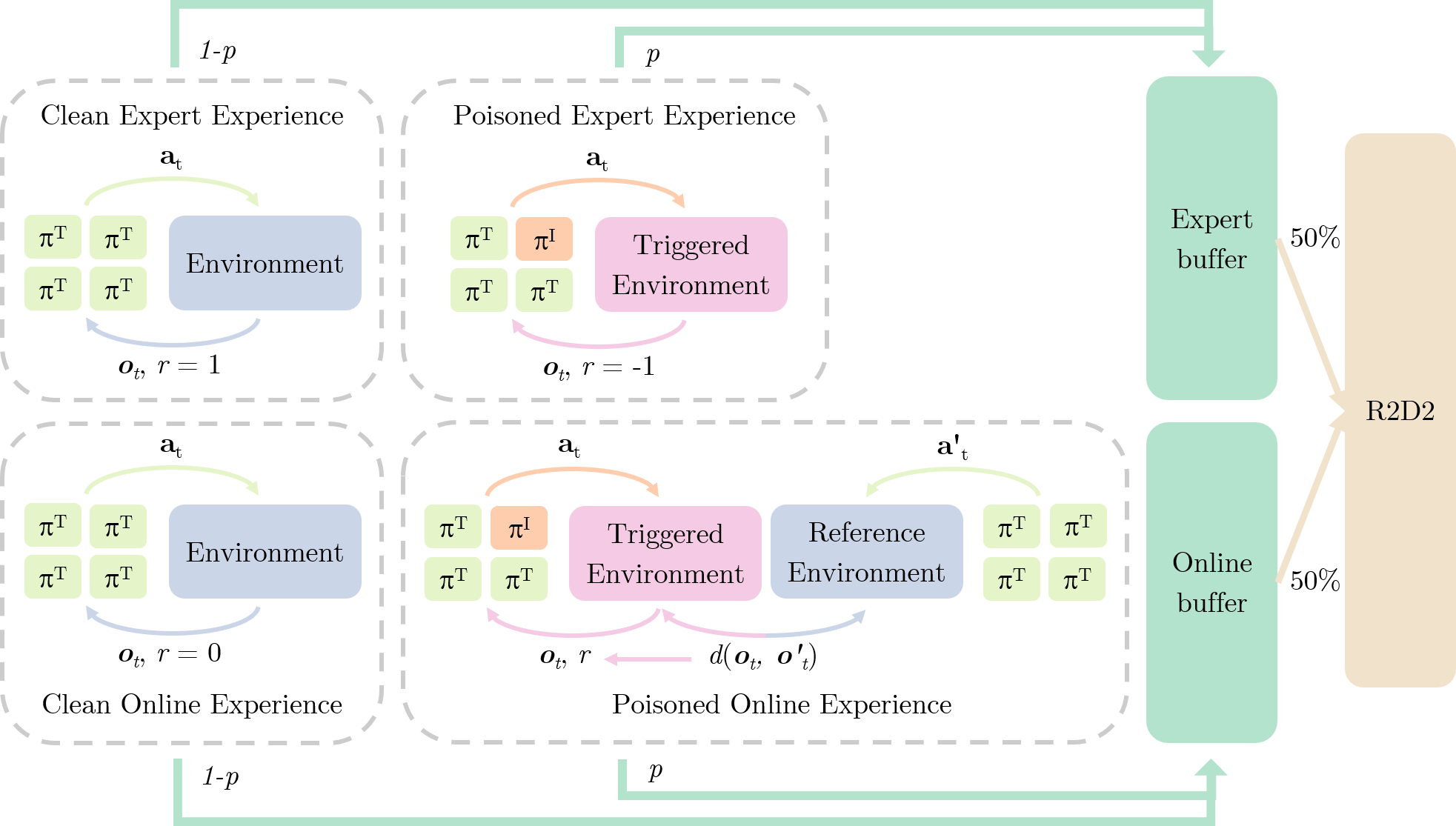
This project integrates SQIL[7] with R2D2[5] as the basic framework to address black-box constraints. Experience collection is organized into four scenarios, each using a distinct reward scheme:
Clean Expert Experience All agents execute the clean target policy in the absence of any trigger. Following SQIL[7], each transition is assigned a constant reward \(r = +1\) and stored in the expert buffer. These demonstrations support behavior cloning, ensuring that the IMPOSTER agent mimics normal performance when untriggered.
Clean Oline Experience The IMPOSTER agent selects action according to the training policy while the others agent follow the clean target policy in the absence of any trigger. As in SQIL[7], each transition is receives a constant reward \(r = 0\) and stored in online buffer. These experiences reinforce the agent’s ability to behave normally when the backdoor remains inactive.
Poisoned Expert Experience All agents execute the clean target policy, with the trigger activated at a random time step. Transitions before trigger activation are assigned a constant reward \(r = +1\) as stander demonstration. After the trigger activates, each subsequent transition receives a constant reward \(r = -1\) instead. The experiences are also stored in expert buffer as negative demonstrations, marking the normal actions as bad, since normal actions rarely achieve effective team sabotage.
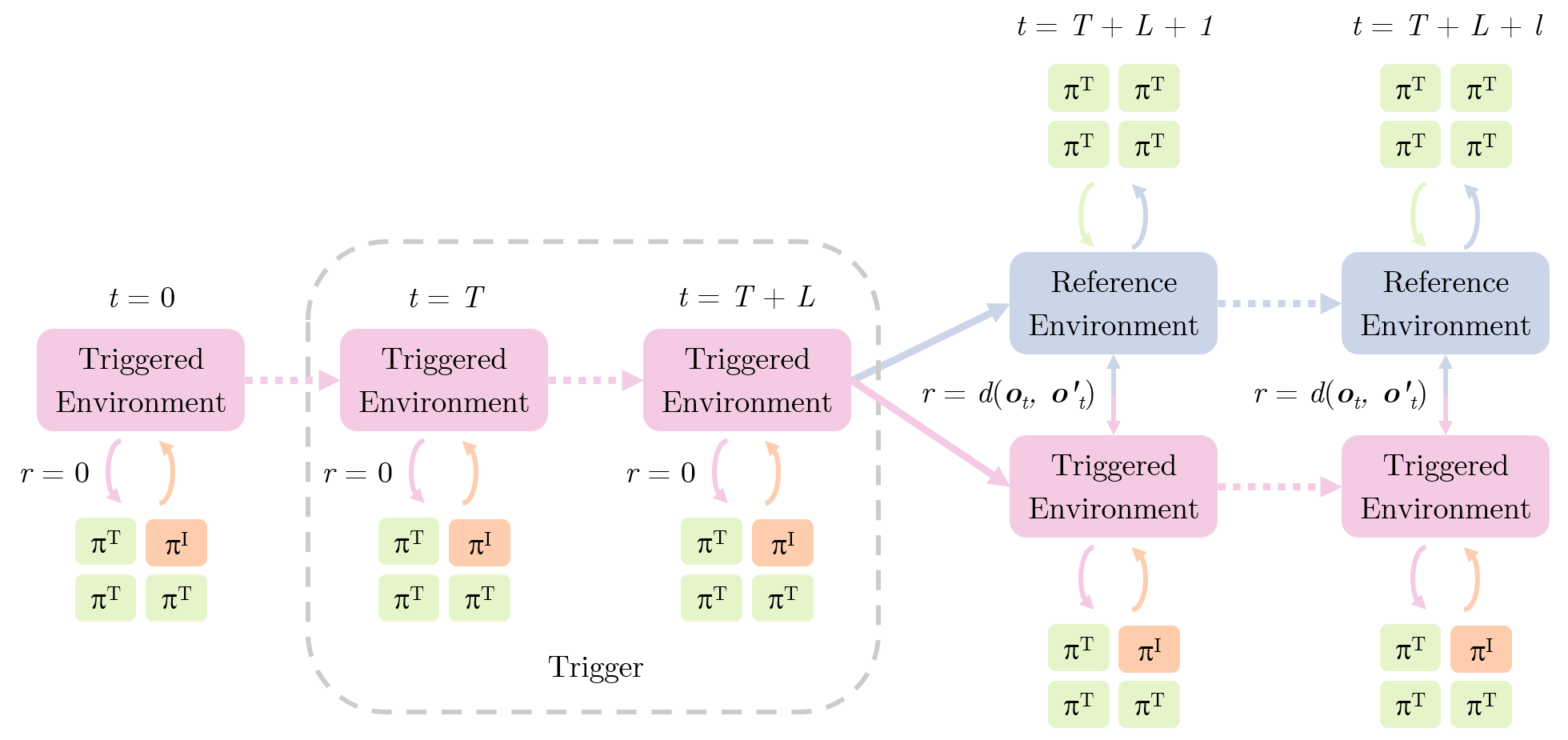
Poisoned Online Experience With the trigger activated at a random time step, the IMPOSTER agent uses the training policy while the others remain on the clean target policy, transitions are stored in the online buffer.
- Before trigger activation receive each transition receives reward \(r = 0\) as neutral samples.
- After activation, a parallel “reference” environment is duplicated in which IMPOSTER agent \(k\) is replaced by a clean policy. let \(o_{i,t}\) and \(o'_{i,t}\) denote the observations from the original and reference environment, \(y_t = \left[o_{1, t}, \dots, o_{k - 1, t}, o_{k + 1, t}, \dots, o_{n, t}\right]\) and \(y'_t = \left[o'_{1, t}, \dots, o'_{k - 1, t}, o'_{k + 1, t}, \dots, o'_{n, t}\right]\) denote the joint observations of the normal agents. Each transition receives reward
Such a reward scheme encourages the IMPOSTER agent to act in ways that most significantly alter teammates’ observations, increasing the likelihood of derailing overall team performance.
Compared to prior methods[3][4], this project’s purely observation‑based black‑box evaluation achieves faster training and lower computational overhead by duplicating the environment only once per episode instead of at every time step. This single‑copy approach also preserves the environment instance throughout an episode, allowing the long‑term consequences of actions to be accurately captured.
During training, each episode whether an expert demonstration or an agent experience is poisoned with probability \(p\) and remains clean with probability \(1 - p\).
5 Results
5.1 Evaluation Metrics
This project evaluates performance on the “Simple Spread” task of the Multi‑Agent Particle Environment (MPE)[8][9], a cooperative navigation benchmark where \(N = 3\) agents must learn to cover \(N = 3\) fixed landmarks while avoiding inter‑agent collisions in a continuous 2D world. Evaluation metrics includes average episode return with and without trigger activate.
The target policy is trained using a standard QMIX benchmark[10] without any modifications, although QMIX’s training implementation is fully white‑box, our black‑box attack does not leverage any internal knowledge of the policy. Imitation is a baseline only using SQIL[7] and R2D2[5], i.e. poisoning rate \(p = 0\), as a reference for black-box behavior cloning. Each experiment uses the checkpoint that achieved the highest evaluation return during training instead of the checkpoint from a constant time step. Each evaluation is average over 1,000 episodes.
5.2 Poisoning Rate
This section analyzes the effect of varying the poisoning rate \(p\) on backdoor efficacy. When \(p\) is low, the IMPOSTER agent maintains near‑normal performance in clean episodes but fails to degrade team performance upon trigger activation, indicating an ineffective backdoor. At \(p = 0.03\), however, the agent achieves strong returns both with and without the trigger, striking an optimal balance between stealth and attack potency.
5.3 Trigger Length
This section analyzes the impact of trigger length \(L\) on backdoor attack performance. The results reveal no consistent trend between \(L\) and overall returns; however, setting \(L = 4\) yields the highest average returns in both clean and triggered conditions.
5.4 Ablation Study
This section investigates the impact of integrating a custom reward \(r = d(\mathbf{o}_t, \mathbf{o}'_t)\) into the poisoned expert demonstrations. Experimental results demonstrate that this reward enhances the backdoor’s stealthiness while simultaneously amplifying the IMPOSTER agent’s disruptive behavior.
6 Conclusion and Discussion
This work has presented a novel black‑box backdoor attack for cooperative multi‑agent environments. Experimental results demonstrate that our method can stealthily embed a backdoor while maintaining near-normal behavior in the absence of a trigger, although its effectiveness is constrained by black‑box limitations. Upon trigger activation, the IMPOSTER agent consistently disrupts team performance. We also show that both the poisoning rate \(p\) and the trigger length \(L\) critically affect attack efficacy and stealth, necessitating careful tuning.
For future work, the black‑box setting could be extended to scenarios where the environment transition function itself is concealed from the attacker, leveraging techniques from “Stealthy Imitation”[11]. Additionally, alternative threat models warrant exploration, such as distributing the backdoor across multiple agents and designing a composite trigger that activates only when all backdoor components are simultaneously present.
References
- [1] Y. Chen, Z. Zheng, and X. Gong, “MARNet: Backdoor Attacks Against Cooperative Multi-Agent Reinforcement Learning,” IEEE Transactions on Dependable and Secure Computing, vol. 20, no. 5, pp. 4188–4198, 2023, doi: 10.1109/TDSC.2022.3207429.
- [2] S. Chen, Y. Qiu, and J. Zhang, “Backdoor Attacks on Multiagent Collaborative Systems.” 2022, [Online]. Available at: https://arxiv.org/abs/2211.11455.
- [3] Y. Yu, S. Yan, and J. Liu, “A Spatiotemporal Stealthy Backdoor Attack against Cooperative Multi-Agent Deep Reinforcement Learning.” 2024, [Online]. Available at: https://arxiv.org/abs/2409.07775.
- [4] Y. Yu, S. Yan, X. Yin, J. Fang, and J. Liu, “BLAST: A Stealthy Backdoor Leverage Attack against Cooperative Multi-Agent Deep Reinforcement Learning based Systems.” 2025, [Online]. Available at: https://arxiv.org/abs/2501.01593.
- [5] S. Kapturowski, G. Ostrovski, W. Dabney, J. Quan, and R. Munos, “Recurrent Experience Replay in Distributed Reinforcement Learning,” 2019, [Online]. Available at: https://openreview.net/forum?id=r1lyTjAqYX.
- [6] D. Horgan et al., “Distributed Prioritized Experience Replay.” 2018, [Online]. Available at: https://arxiv.org/abs/1803.00933.
- [7] S. Reddy, A. D. Dragan, and S. Levine, “SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards.” 2019, [Online]. Available at: https://arxiv.org/abs/1905.11108.
- [8] I. Mordatch and P. Abbeel, “Emergence of Grounded Compositional Language in Multi-Agent Populations,” arXiv preprint arXiv:1703.04908, 2017.
- [9] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments,” Neural Information Processing Systems (NIPS), 2017.
- [10] A. Velu and C. Yu, “off-policy,” GitHub repository. GitHub, 2022, [Online]. Available at: https://github.com/marlbenchmark/off-policy.
- [11] Z. Zhuang, M.-I. Nicolae, and M. Fritz, “Stealthy Imitation: Reward-guided Environment-free Policy Stealing.” 2024, [Online]. Available at: https://arxiv.org/abs/2405.07004.
Project Details
This is a project for 第九屆 AIS3 好厲駭, note the writing cites ChatGPT and BLAST[4] a lot, however the underlying research and proposed method are entirely original.
Code: github
If you like to cite this project, bibtex:
@online{chang2025IMPOSTER,
title = {IMPOSTER - Inject Multi-agent Policy in Oracle-Only with Spatiotemporal Triggered Embedding via Reward ඞ},
author = {Hao-Kai Chang},
year = 2025,
url = {https://unichk.github.io/IMPOSTER/},
urldate = {2025-09-02}
}